Advisor Perspectives welcomes guest contributions. The views presented here do not necessarily represent those of Advisor Perspectives.
To optimize portfolios, the investment and wealth management industry still assumes a random walk of prices when running long-term simulations of equity portfolios, despite plenty of existing research pointing to serial dependency in returns.
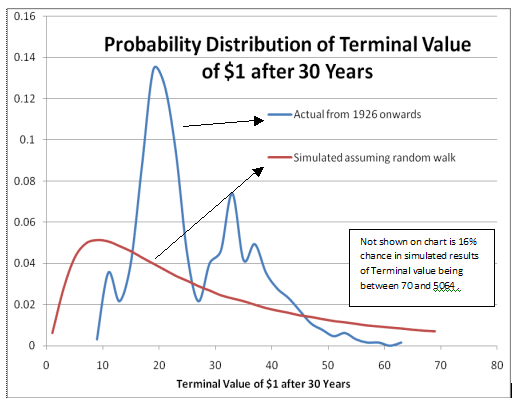
The random walk assumption for equities gives results that are counterintuitive and unobservable in practice. I recommend against using it. For example, $1 invested in large-cap stocks over thirty-year rolling windows has never grown to a terminal value outside the range of $8-$64, but a simulation assuming random walk assigns that event a probability of 29%.
The following chart shows the distribution of the terminal value of $1 invested in a large-cap stock index over thirty years (with dividends reinvested) from two sources – the observed historical distribution of returns over rolling thirty-year windows is overlaid on the predicted distribution given by a simulated thirty-year investment horizon that assumes random walk.
Chart #1: Probability Distribution of Terminal Value of $1 invested in Large Stock Index for 30 years – observed historical distribution vs. distribution of simulated results

The two distributions in chart 1 are plainly different. Throughout the time period from 1926 to 2009, if you had invested $1 at the end of any calendar month, you would have always walked away with a terminal value, 30 years later, in the range of $8-$64. That is, history shows zero probability of the terminal value being outside that range. A simulation with the assumption of a random walk, though, assigns that outcome almost a one-in-three chance. Even the peaks of the distributions of the terminal values are different: the most common outcome historically has been a terminal value between $18 and $22, with a probability of 26%. The peak of the simulated distribution is between $8 and $12, with a probability of 10%.
How many of you would expect that after a thirty-year investment horizon in a large-cap stock index, you would have a nominal loss? I suspect nobody expects that outcome, even taking into account the volatility of stocks. A simulation using a random walk assumption, however, assigns a 0.6% chance to having a nominal loss after thirty years?
All of the above suggests that the random walk assumptions underlying the simulation are flawed. We should not assume random walk when simulating a stock portfolio over horizons as long as thirty years. Flawed simulation results seem likely to prompt a wrong decision.
William Jahnke, in his chapter on “Death to the Policy Portfolio” in the book The Investment Think Thank, edited by Evensky and Katz, points to research articles that disclaim the random walk theory and suggest serial dependency in returns. Jhanke quotes a Fama and French 1991 study that found a “large negative auto-correlation for return horizons greater than one year.”
Peter Bernstien, in his book Against The Gods: The Remarkable Story Of Risk, mentions a 1995 AIMR article by Reichenstein and Dorsett that concluded “bad periods in the market are predictably followed by good periods and vice versa” The extensive research pointing to serial dependency in stock market returns notwithstanding, however, I see frequent use of the random walk assumption in the wealth and investment management industry when simulating stock portfolios over long horizons.
The empirical evidence in chart 1 shows that the random walk assumption yields implausible results. Let’s now analyze why this assumption is incorrect.
Let’s walk through the mechanics of a simulation using the random walk assumption to help understand how we obtained chart 1. Suppose we want to simulate a thirty-year investment horizon using a monthly return distribution from the past as the guiding distribution (an actual discrete distribution of the past that is not boxed into a continuous statistical distribution). The random walk assumption says it would be acceptable to choose any historical monthly return as the random draw for the first month. Similarly, for the second month, we again randomly draw any monthly return from the historical discrete return distribution and keep on repeating this process for thirty years.
The monthly total returns for large-cap stocks from 1926 onwards show that there is a 1% chance of monthly loss of 15% or higher. Suppose we draw a return of -19% (the monthly return for October 1929). The random walk assumption implies that the chance of the next month’s return being less than -15% is still one percent. Assume that one percent chance event happened again and the next month’s return draw is -16% (June 1930). If we run this process for twenty months and by stroke of luck, we end up drawing a return of less than -15% for twenty months in a row, the random walk assumption implies that the probability of choosing a -15% or lower return for the 21st month is still the same, one percent. Don’t you think that in this hypothetical situation, where the stock market for a country like United States falls by 96% (calculated as 15% loss for twenty months in a row), the chance of having a large negative return the next month is nil?
In practice, when the economy goes south and the stock market tanks, investors quite often overreact, meaning the market reaches lower levels than are rational. But policy action typically will kick in and try to arrest the economic downfall. So, after a series of high negative returns, the chance of having positive monthly returns far outweighs the chance of a negative return.
I hope I have convinced you not make random walk assumptions when doing long-term simulations for equity portfolios. What is the alternative? This depends on the purpose of the simulation, and an answer will require more research. But it’s clear that a better scenario-generation technique for long-term simulation is needed in the wealth and investment management industry, and it needs to be one that recognizes returns’ reversion to the mean, the limitations on how economies and corporate earnings grow or fall, and other factors that I plan to outline in a subsequent article.
The difficulty of generating accurate scenarios doesn’t detract the usefulness of Monte Carlo simulations in making the right decisions for things like retirement distribution financial planning, where the sequence of returns affect the success of the distribution plan, but we as an industry need to improve the scenario-generation technique for Monte Carlo simulations. My preference is for a methodology that advisors can understand and explain to their clients. I have received very good suggestions already from people who have reviewed drafts of this article, and I encourage all readers of this article to me your suggestions.
Manish Malhotra, is an Engineer-MBA, Level III candidate in the CFA program, with twelve years of experience in banking, risk and wealth management working on both business and IT.
Appendix A
Data sources and simulation methodology
Monthly total returns (capital appreciation return and income return) series for the large-cap stock index were obtained from the 2010 Ibbotson SBBI Classic Yearbook that provides this data from Jan 1926 to Dec 2009. Calculation of the terminal value assumes all dividends are reinvested.
The same monthly total return distribution was used for simulation. To get each month’s total return, a return from the monthly return series (Jan 1926 to Dec 2009) is randomly chosen. Again, the terminal value of $1 was calculated assuming reinvestment of all monthly dividends. One million independent simulations were carried out for a thirty-year period (360 months) using monthly total returns and the distribution of terminal value observed is plotted on the chart.
In my observations, the simulated terminal value distribution gains some degree of stability after 100,000 simulations. I ran one million independent simulations to make sure the distribution has higher degree of stability. Anybody trying to replicate the study should try a million simulations rather than a small subset like 10,000.
Medium of analysis
The calculations were done in Java, not in a worksheet. I find using a programming language to be a more productive way of doing the analysis, especially when one is going through iterative prototyping with various perspectives. I am happy to share my Java source code, compiled version and underlying source data files for anybody interested in auditing the work or doing further work. Email me .
Distribution charts
The distribution of terminal value observed is arranged in ranges to calculate the frequency and probability of being in that range. Those range distributions were plotted using Excel to give a smooth look rather than a histogram. The average of the terminal value range is used on the x-axis and the observed probability of the terminal value being in that range is used for the y-axis.
Rolling periods
Let me explain rolling period return distributions via an example. Let’s say we invest $1 at the end of Jan 1970 and reinvest dividends received until the end of Jan 2000. Measure the value of the holding at end of Jan 2000. That gives us one data point for a thirty-year analysis. Now, roll forward one month and calculate terminal value of $1 invested at the end of Feb 1970 until the end of Feb 2000. That gives us a second thirty-year data point. Keep on rolling one month forward. That gives a thirty-year series with its own distribution.
Comparison of rolling-period historical analysis to simulated results
Since there aren’t enough independent thirty year periods to fully analyze a thirty-year time horizon, I used a rolling period analysis. A rolling-period analysis introduces observations that are not independent, but it is still useful, because it captures the volatility of the stock market well enough. Because equity market returns exhibit regression to the mean, the rolling period analysis gives a good sense of the distribution around the long-term mean.
My simulation results, on the other hand, are completely independent observations.
Despite the limitations of rolling-period analysis, I believe the empirical observations made in the article are still meaningful. The recommendation against using the random walk assumption for a long-term simulation is not purely based on empirical results; it has an analytical foundation as well. The empirical results simply illustrate effectively and lend extra weight to the analytical argument.
Definition of the Random Walk assumption
Most common interpretation of the Random Walk assumption for the stock market is that returns in future periods are not dependent on prior periods. That is the layman’s definition I use in this article, and a more precise definition in mathematical terms is outlined in the next paragraph. Others have used different definitions of a Random Walk. Burton Malkiel, in his book A Random Walk Down Wall Street, says, “When the term is applied to stock market, it means that short-run changes in stock prices cannot be predicted.” Malkiel qualifies his definition to the short-run. As I have said before, I have seen the wealth management industry apply the assumption to long-run change in stock prices, too.
William Jahnke, in the material referenced earlier in the article, quotes Louis Bachelier who describes three properties of a Random Walk model: independent, identically distributed and normally distributed. In this article, I use two parts of the definition, omitting the requirement that returns be normally distributed. My reason for doing this is that I have seen the wealth and investment management industry recognize that return distributions are not normally distributed and do in fact exhibit fat tail distributions. But I haven’t seen many instances of the industry practicing a scenario generation technique that factors in serial dependency of returns or lack of stability into the return-generating process – that is, the industry continues to work on the assumption that returns are independent and identically distributed.
I want to thank Michael Edesess, Sam Savage, Cameron Hight, Jonathan Clements, Joel Bruckenstein, Mark Snodgrass and Arturo Rodriguez for their extremely valuable feedback on earlier drafts of this article.
Read more articles by Manish Malhotra